The Challenge of Scale
As AI applications mature from prototypes to production systems serving millions of users, a critical question emerges: How do you balance cost, latency, and quality when every query matters?
The naive approach—routing all requests to a single "best" model—quickly becomes untenable. High-end models like GPT-5 or Claude are excellent but expensive and slower. Lightweight models are fast and cheap but may struggle with complex reasoning. The solution? Intelligent routing across multiple LLMs.
The Routing Problem: Why It Matters
Consider a typical AI assistant handling diverse queries:
- "What's 2+2?" (trivial)
- "Summarise my emails from today" (simple)
- "Analyse this codebase and suggest architectural improvements" (complex)
- "Schedule a meeting with Sarah tomorrow at 2pm" (task-specific)
Routing all these through the same model is like using a Formula 1 car for grocery runs—technically capable, but wasteful. The key insight: Different queries have different requirements. The economics speak for themselves:
- GPT-5: ~$1.3-$10 per million tokens
- Claude Sonnet: ~$3-$15 per million tokens
- GPT-4o-mini: ~$0.08 per million tokens
Without intelligent routing, you're either overpaying by 10-50x or compromising quality by always using the cheapest option.
Routing Strategy #1: Difficulty-Based Routing
Route queries to different models based on their complexity, matching task difficulty to model capability. For this you can use a three-tier system with a lightweight classifier model making routing decisions:
pythonmodels = { "high": { "model_name": "claude-4-5-sonnet", "specialties": ["math", "code", "creativity", "complex reasoning"], "cost": "high", "latency": "high" }, "medium": { "model_name": "gemini-2.5-flash", "specialties": ["general", "creativity", "code", "balanced performance"], "cost": "medium", "latency": "medium" }, "low": { "model_name": "gpt-5-nano", "specialties": ["quick responses", "simple tasks", "high throughput"], "cost": "low", "latency": "low" } }
Real-World Examples
Example 1: Customer Support System
markdownQuery: "What are your business hours?" Classification: LOW → gpt-5-nano Cost: $0.0001 | Latency: 200ms
Potential savings: On a typical support workload (70% simple, 20% medium, 10% complex), this approach yields 60-70% cost reduction compared to routing everything through a high-end model.To keep these cost reduction figures we need to consider the Classifier Model. We use Gemini 2.5 Flash Lite as the classifier—model mainly because of:
- Extremely low latency
- Minimal cost (pennies per thousand classifications)
- Smart enough to distinguish complexity levels
The classifier's cost is negligible compared to the savings it enables.
Routing Strategy #2: Agent-Based (Task-Type) Routing
The Concept
Route queries to specialised agents based on the type of task, where each agent has access to specific tools and is optimised for particular domains. This is how we implement it:
pythonagents = [ { "name": "Email Assistant", "agent_code": "email_assistant", "tasks": ["Access emails", "Send emails", "Summarise inbox"], "best_for": "Email related tasks" }, { "name": "Calendar Assistant", "agent_code": "calendar_assistant", "tasks": ["Create events", "Update events", "Send invites"], "best_for": "Calendar related tasks" }, ]
Real-World Examples
Example 2: Executive Assistant Application
markdownUser Query: "What emails did I get today?" → Routes to: email_assistant → Agent capabilities: Gmail API access, summarisation → Response: Summarised list of today's emails with priorities
Why This Matters:
- Tool Access Control: Email agent has Gmail credentials, calendar agent has Calendar API access—proper security boundaries
- Context Optimisation: Each agent's prompt includes domain-specific context, reducing token usage
- Specialised Fine-tuning: Agents can be fine-tuned for their specific domains
- Parallel Scaling: High-traffic domains (e.g., email) can have dedicated infrastructure
Routing Strategy #3: Hybrid Routing (The Power Combo)
The most sophisticated approach combines both strategies—first route by task type, then by difficulty within that domain.
Architecture
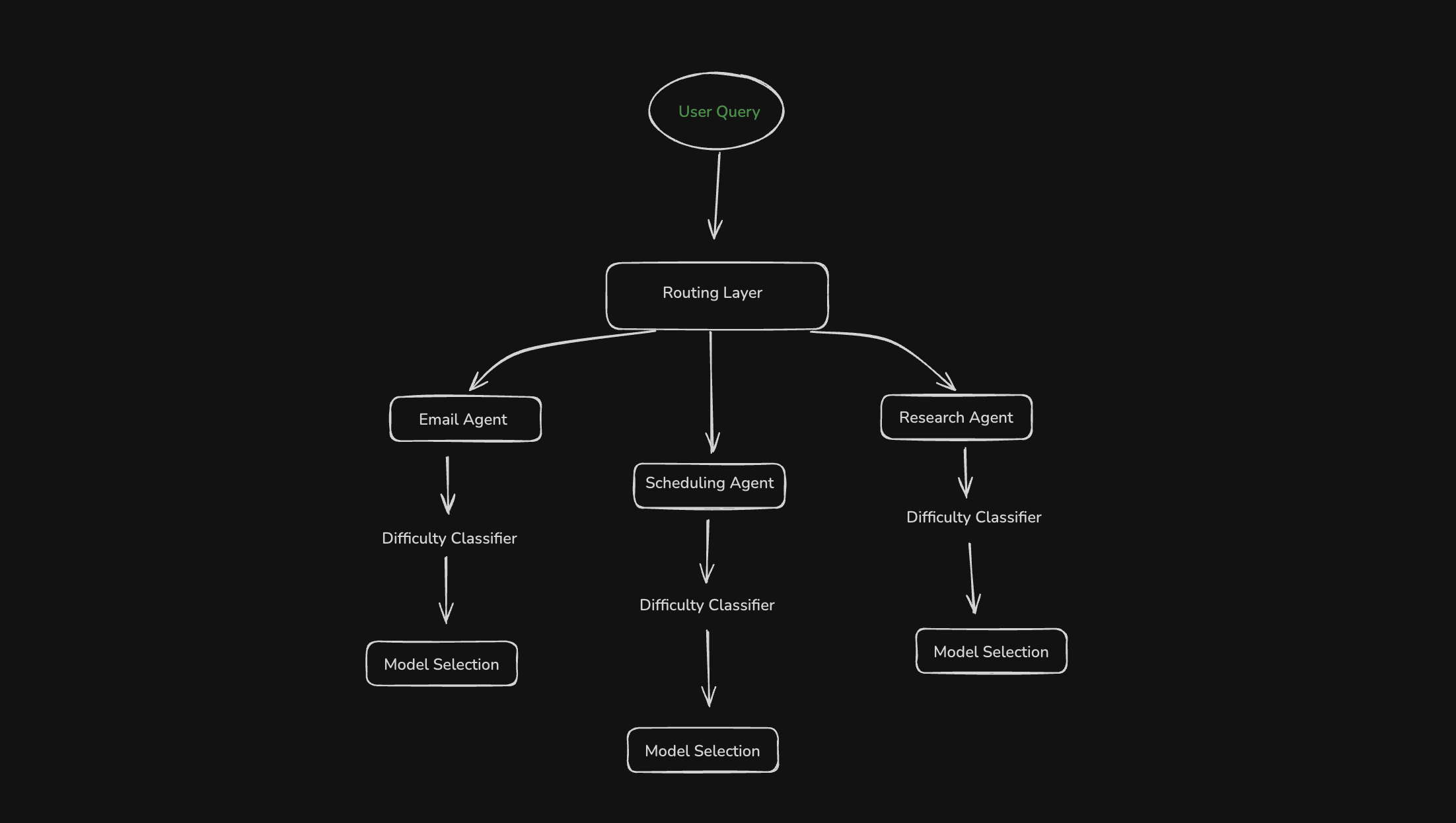
Example 3: Multi-Dimensional Routing
markdownQuery: "Summarise my inbox" → Task Router: email_assistant → Difficulty: LOW (simple summarization) → Final Model: gpt-4o-mini → Cost: $0.0002 | Latency: 300ms
Advanced Routing Considerations
1. Fallback Strategies
In production systems, fallback logic is crucial:
- Classification timeout → default to medium-tier model
- Model unavailable → cascade to backup model
- Ambiguous classification → choose higher capability to ensure quality
2. Latency vs. Quality Trade-offs
For different use cases, optimise differently:
| Use Case | Priority | Routing Strategy |
|---|---|---|
| Chatbot (sync) | Latency | Aggressive low-tier routing |
| Content generation (async) | Quality | Aggressive high-tier routing |
| Search autocomplete | Latency | Always lowest tier |
| Legal document review | Quality | Always highest tier |
3. Cost Monitoring and Circuit Breakers
Implement guardrails:
pythondef route_with_budget(prompt, monthly_budget_used): if monthly_budget_used > 0.9: # 90% of budget spent # Force all requests to low-cost models return "gpt-4o-mini" else: # Normal routing logic return classifier.classify(prompt)
4. Continuous Learning from Routing Decisions
Log every routing decision with outcomes:
- Was the model selection appropriate?
- Did the user request regeneration? (signal of poor routing)
- Quality metrics on responses
Use this data to:
- Fine-tune your classifier
- Adjust routing thresholds
- Identify new routing patterns
Key Takeaways
- Start Simple: Begin with difficulty-based routing across 2-3 models
- Measure Everything: Track cost, latency, and quality metrics per route
- Use a Fast Classifier: Your routing overhead should be < 200ms
- Build in Fallbacks: Production systems fail gracefully
- Iterate Based on Data: Your initial routing rules will be wrong—that's okay
Aether's Architecture Principles
The Sulta Tech team designed Aether (Our AI Router) with two core principles in mind. First, high throughput classification ensures that the routing layer maintains the lowest possible latency. Second, extensibility makes it trivial to add new models or agents to the system. Lastly, observability to monitor and improve the systems routing decisions.
The Future of LLM Routing
As the LLM ecosystem matures, routing will become increasingly sophisticated and necessary. Emerging patterns are already reshaping how we think about model orchestration. Multi-model consensus routes critical decisions to multiple models simultaneously, synthesising their responses for higher confidence outcomes—a pattern exemplified by the recent release of Cursor 2.0, which allows coding agents to work in parallel and has demonstrated significant quality and speed boosts in real-world workflows. Reinforcement learning routers take this further by learning optimal routing policies directly from user feedback over time. Context-aware routing adds another dimension by considering user history, time of day, and subscription tier when making routing decisions. Finally, specialised model ecosystems leverage domain-specific models, routing queries based on the unique capabilities each model brings to particular problem domains.
Conclusion: Routing is Product Strategy
Multi-LLM routing isn't just a technical optimisation—it's a product strategy. The right routing system lets you:
- Deliver better user experiences (faster responses for simple queries)
- Scale sustainably (10x reduction in infrastructure costs)
- Maintain quality (complex queries get powerful models)
- Build competitive moats (routing intelligence becomes your secret sauce)
Aether, built by the engineering team at Sulta Tech, demonstrates that effective routing doesn't require complex ML pipelines or massive infrastructure. A lightweight classifier, thoughtful model selection, and clear routing strategies can transform your AI system's economics.
*Built by engineers at Sulta Tech
Additional Resources
Want to discuss multi-LLM architecture for your system? The Sulta Tech team is available for consulting and can help you design routing strategies tailored to your specific use case and constraints.